Datadelingsplattform
Følg opp FN's bærekraftsmål og slutt å kopiere data.
I dag er 90% av eksplosjon i data bare kopi - og ikke nye data!
Ta tak i alle data der de er, uten behov for ETL eller å kopiere data.
Start med Analyser og AI i løpet av uker istedet for måneder og år.
Klar for sky og kan implementeres på MS Azure, Google, AWS osv.

Rask tilgang til relevant data
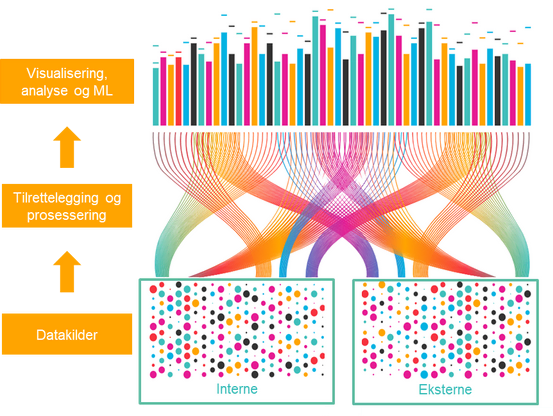
TIBCO Data Virtualization gir rask tilgang til alle relevante data. Data kan være lokalt i eget datasenter eller hos en, eller flere Skyleverandør. Vi har adaptere til alle relevante leverandører og applikasjoner. Det unike er at vi opphever bruk av ETL og behov for å kopiere data. Ved å plassere et tynt forretningslag over dataene dine, gjør det de enklere å finne, forstå og bruke. Dataene hentes når det spørres og trenger ikke å flyttes eller kopieres for at en rapport skal bli ferdig eller en aksjon trigges.
Alle TIBCO produkter er klargjort for Sky og de fleste kunder har implementert dette hos sin prefererte Skyleverandør.
En skisse av mulighetene ser dere nedenfor:
-
RICK VAN DER LANS: DATADELING PÅ EN ENKEL MÅTE
-
KILDER - VI STØTTER ALLE ON PREM - OG ALLE SKYLEVERANDØRER

-
HVORDAN IMPLENTERE LØSNINGE
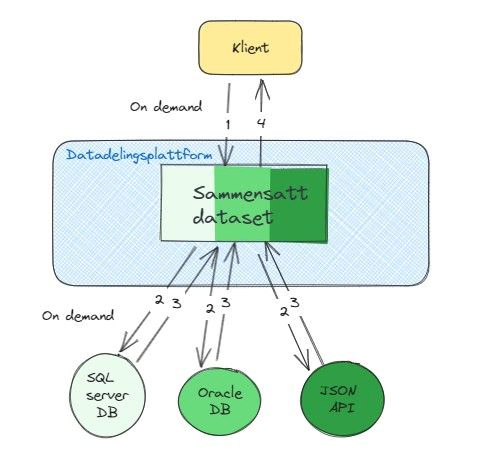
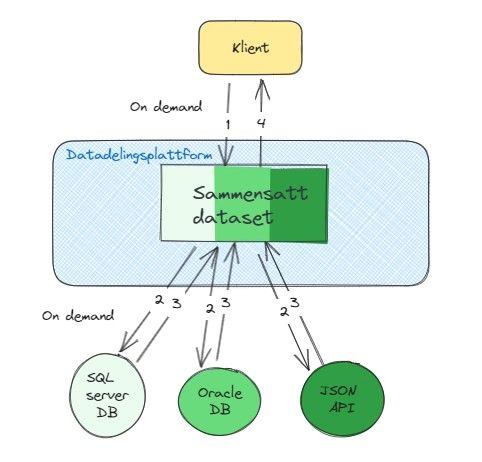
Plattform med mange muligheter
- Sammenstille data fra fysiske datavarehus med data fra andre datakilder med minst mulig innsats.
- Tilby nye data til analyse- og innsiktsformål raskt og effektivt.
- Fleksibilitet ift. å ta i bruk nye klientverktøy og datakilder.
- Ha én definisjon på alle dataelementer og ha dem samlet ett sted.
- Samle mest mulig forretningslogikk ett sted, i et felles ikke-proprietært semantisk lag og reduser behov for utvikling, test og feilsøking/-retting.
- Bygge en datakatalog og få samlet alle definisjoner innen. områdene datavarehus, analyse og innsikt ett sted som er lett tilgjengelig for applikasjoner og brukere.
- Koble sammen data fra forskjellige typer kilder; strukturerte data, semi-strukturerte data, ustrukturerte data, data med store volumer, data som endres raskt og komplekse datastrukturer.
- Understøtte smidig prototyping og sandboxing.
- Sikre raskere time-to-market når for nye data og dataprodukter.
- “Bring your own tool”, gjøre sluttbrukeren i stand til å koble seg til et omforent datalag fra en hvilken som helst sluttbrukerapplikasjon.
- Kontroller ressurs bruk på underliggende kilder.
- Finmasket tilgangskontroll og datamaskering på toppen av alle datakilder.
- Opprett sikre API-er til legacy systemer og all annen informasjon